
In my last post I set out some peculiar requirements for a search data-structure and investigated how well a treap would fit those requirements. To re-cap, here were the requirements:
O(log N) or better insertions and lookups.I alluded that there are data-structures that fulfill my needs while being even simpler and even faster. In this post I'll describe two of these:
One of the key observations on the last post was the treap works due to a well
distributed heap priority.
Another observations was that instead of a PRNG we can use a hash function since
"good hash functions" are supposed to have well distributed hashes.
Now in our case, we don't really need the tree to be sorted by the key since we only care about insertions and lookups. Which leads to the following observation: there's no need to maintain a heap property. Instead we can just use the hash of the key to order the BST directly.
Because the hashes are supposed to be fairly well distributed already, a BST built from sorting on the hash will thus end up fairly balanced too.
typedef struct BHTNode {
Str key;
u64 hash;
struct BHTNode *child[2];
} BHTNode;
static BHTNode *
bht_find(Arena *a, BHTNode **t, Str key)
{
u64 hash = str_hash(key);
BHTNode **insert = t;
while (*insert != NULL) {
u64 phash = insert[0]->hash;
switch ((hash > phash) - (hash < phash)) {
case 0: if (str_eq(key, insert[0]->key)) return insert[0]; // fallthrough
case -1: insert = insert[0]->child + 0; break;
case +1: insert = insert[0]->child + 1; break;
}
}
if (a != NULL) {
*insert = arena_alloc(a, sizeof **insert);
**insert = (BHTNode){ .key = key, .hash = hash };
}
return insert[0];
}
And this is it, the entirety of the code required to implement a "binary hash tree".
How does it perform compared to the treap from last post? Using the same benchmarking format as last time, here's some results:
| Items-Name | Insert | SLookup | RLookup | Mem (KiB) |
|---|---|---|---|---|
| 512-Treap | 53 | 63 | 39 | 16 |
| 512-BHTree | 34 | 51 | 58 | 20 |
| 2048-Treap | 250 | 288 | 226 | 64 |
| 2048-BHTree | 220 | 230 | 230 | 80 |
| 16384-Treap | 3008 | 3134 | 3168 | 512 |
| 16384-BHTree | 2267 | 2303 | 2543 | 640 |
| 131072-Treap | 40804 | 45579 | 66662 | 4096 |
| 131072-BHTree | 25849 | 30606 | 29721 | 5120 |
| 1048576-Treap | 650847 | 735479 | 1275253 | 32768 |
| 1048576-BHTree | 362686 | 418937 | 521011 | 40960 |
In pretty much all cases, the binary hash tree outperforms the treap.
The memory usage is a bit higher due to having to keep the hash member in each
node since recomputing the hash can be expensive.
To get a bit of intuition into how this works, here's a picture of a binary hash tree with 64 elements.
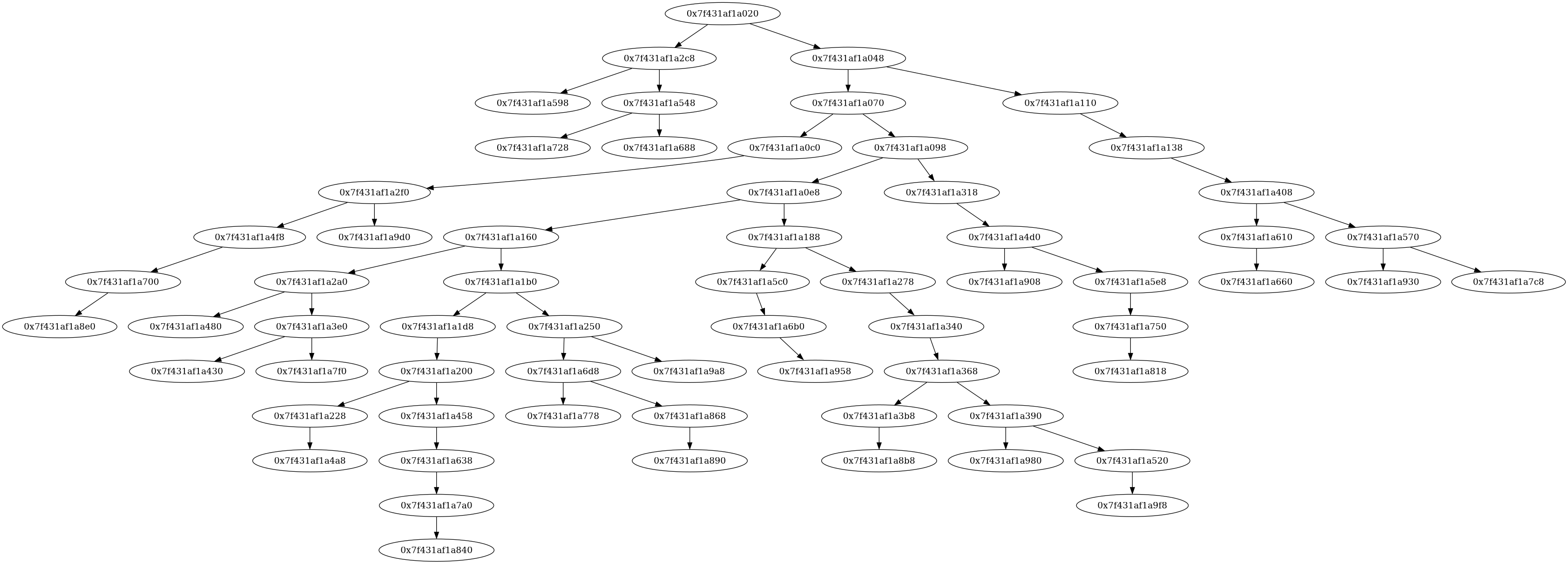
You can see that the tree is far from being perfectly balanced. But it's not too far off either.
Here's another image, this time with 256 elements.

The tree isn't too off balance, although there's a bit of "cluster" forming at the middle. With hash-tables, I've noticed that a "decent" but fast hash function often makes the hash-table faster as a whole compared to a slower but higher quality hash function. But in case of a binary hash tree, getting good distribution out of your hash function seems to be much more important.
But assuming you do have a "good hash function", are you really guaranteed not to degrade into a bad O(n) search? It's not a strong guarantee, but the probability of degrading into massively unbalanced O(n) tree is fairly low.
One intuitive way I like to think about this is that if you have a largely unbalanced tree, that's another way of saying that there were lots of more ideal nodes in the "upper levels" of the tree which weren't taken. Which is another way of saying that those nodes are available for future insertions. And so if you are to insert a random number into the tree, there's a higher chance that it will take a more ideal branch on the upper level instead of descending down to the worst case.
And conversely, if your tree is already fairly balanced, then there's less spots available on the upper levels increasing the chances of a random insert descending down to a bad branch.
The above is an animation of inserting 128 elements into a binary hash tree. You can see how it goes through "cycles" where it becomes more unbalanced leaving lots of holes and then those holes slowly gets filled up by later insertions.
Going along the theme of randomization and even distribution, how about we use
multiple trees instead of just a single one.
And we'll just pick a tree depending on the hash we've already computed.
In other words, a "hash-table of hash-trees" (or HTHTree in short).
Supporting it is trivial, simply change the insert initialization to the
following:
BHTNode **insert = t + (keyhash & (NSLOTS - 1));
And change t from a single tree pointer to an array of pointers.
NSLOTS is the number of slots we have in our array, which must be a power of 2.
16 seems to be a good choice, anything above 32 starts providing diminishing
returns.
Also notice that I'm using the low bits of the hash to index into the hash-table. This is because the high bits will affect the binary tree comparison the most and the low bits are mostly going to be ignored. And so I'm making use of the low bits rather than the high.
| Items-Name | Insert | SLookup | RLookup | Mem (KiB) |
|---|---|---|---|---|
| 64-BHTree | 6 | 9 | 6 | 2 |
| 64-HTHTree | 3 | 5 | 4 | 2 |
| 128-BHTree | 10 | 18 | 12 | 5 |
| 128-HTHTree | 6 | 11 | 9 | 5 |
| 256-BHTree | 17 | 25 | 26 | 10 |
| 256-HTHTree | 14 | 23 | 21 | 10 |
| 512-BHTree | 36 | 52 | 47 | 20 |
| 512-HTHTree | 29 | 47 | 40 | 20 |
| 1024-BHTree | 76 | 111 | 100 | 40 |
| 1024-HTHTree | 64 | 100 | 82 | 40 |
This provides some decent speed up at small Ns (common case).
At large Ns, the "acceleration" provided by the hash-table becomes negligible
because the O(log N) tree dominates.
Given how easy it is to support a "root level hash-table" and the fact that it's strictly a win rather than being a trade-off, it probably doesn't make much sense not to do it.
The idea of making a BST out of hash seemed like a simple but effective idea. And so I started to search for any existing data-structure that does this but I couldn't quite find any. This does make sense because:
Hash array mapped trie (or HAMT) is a data-structure that takes the 2nd approach. Instead of a sorted tree, it's a trie of hashes. Describing HAMT in details is a bit out of scope for this article, but here's a short description (of what I gathered out of the wikipedia article and this talk by Phil Nash):
For example, if you picked 4 as the size of the array, then you'd take 2 bits
out of your hash each time you traverse a node as your index.
So if you're looking up or inserting "alpha" which has a 4-bit hash of 0b0111
then you'll take the highest 2 bits (01) as your index.
11 or 3 in our example) to index into that
"next array". .
.Following the above idea, I went ahead and implemented a HAMT with some fairly finicky code.
| Items-Name | Insert | SLookup | RLookup | Mem (KiB) |
|---|---|---|---|---|
| 2048-HTable | 132 | 155 | 134 | 64 |
| 2048-HTHTree | 198 | 217 | 217 | 80 |
| 2048-HAMT | 142 | 177 | 138 | 185 |
| 16384-HTable | 1183 | 1433 | 1241 | 512 |
| 16384-HTHTree | 2180 | 2284 | 2497 | 640 |
| 16384-HAMT | 1330 | 1654 | 1318 | 1491 |
| 131072-HTable | 11864 | 19586 | 14878 | 4096 |
| 131072-HTHTree | 25756 | 31023 | 29675 | 5120 |
| 131072-HAMT | 14716 | 24269 | 18400 | 11730 |
The above was using an array size of 8. The performance here is impressive, it's competing head to head with a pre-allocated hash-table. Lookup performance is really good too.
But the problem is the insanely high memory usage. The original HAMT uses 32 sized array - but it uses a sparse array with a bitmap trick to save space. But that requires resizes, which I have explicitly forbidden. Reducing the array size to 4 makes the memory usage a bit less (at the cost of some performance) but even then the memory usage was crazy high compared to the other options.
Skimming through the original paper it doesn't mention linked-lists. Instead it seems to recommend rehashing the key if a collision occurs.
The performance of HAMT was really good, but the large and finicky implementation combined with the huge memory overhead made me not investigate the ideas behind it any further.
But in a weird turn of events Chris Wellons ended up misunderstanding what I had meant by "hash table of hash trees" and thought that the "hash table" was supposed to be embedded into the leaf rather that at root level as I had intended. And thus he ended up recreating a hash-trie (an idea which I had prematurely abandoned) except it's vastly simpler than my over-engineered and finicky HAMT implementation. Here's the entirety of the code:
typedef struct HTrie {
Str key;
struct HTrie *slots[4];
} HTrie;
static HTrie *
htrie_traverse(Arena *a, HTrie **t, Str key)
{
for (u64 keyhash = str_hash(key); *t != NULL; keyhash <<= 2) {
if (str_eq(key, t[0]->key)) {
return t[0];
}
t = t[0]->slots + (keyhash >> 62);
}
if (a != NULL) {
*t = arena_alloc(a, sizeof **t);
**t = (HTrie){ .key = key };
}
return *t;
}
The hash of the key is used to traverse the trie and after each iteration the used 2 bits of the hash are shifted out. What happens when the hash runs out? It implicitly degrades into a linked list that always takes the 0th slot.
Keep in mind that unlike a chained hash-table, a full hash collisions doesn't necessarily trigger the linear linked list probe. In order for it to degrade, you'd need to exhaust all the nodes in the path of that hash first. That's 32 nodes for a 64-bit hash. In my synthetic tests with 64-bit hashes my system would run out of memory before I could trigger the linked-list condition.
How does it perform?
| Items-Name | Insert | SLookup | RLookup | Mem (KiB) |
|---|---|---|---|---|
| 2048-HTable | 132 | 156 | 139 | 64 |
| 2048-HTHTree | 205 | 214 | 217 | 80 |
| 2048-HTrie | 138 | 168 | 141 | 96 |
| 16384-HTable | 1163 | 1410 | 1229 | 512 |
| 16384-HTHTree | 2152 | 2225 | 2428 | 640 |
| 16384-HTrie | 1373 | 1615 | 1416 | 768 |
| 131072-HTable | 11816 | 19393 | 14526 | 4096 |
| 131072-HTHTree | 24673 | 30075 | 28696 | 5120 |
| 131072-HTrie | 16263 | 24299 | 22545 | 6144 |
Quite a lot better than HTHTree! But without consuming crazy amount of memory compared with HAMT. And the implementation is also really simple and straight forward, unlike my HAMT implementation. This makes Hash-Tries my new favorite search data-structure when array resizes are to be avoided.
Here's a 4-way Hash-Trie with 32 elements:

And here's one with 256 elements (click on the image to see full size):

Notice how wide (and short in height) the trie is compared to the binary hash tree? The significantly better performance shouldn't be a surprise.
I've tried tuning the number of leafs but anything above 4 results in negligible amount of performance win while consuming significantly more memory. And so 4 is going to be a good default.
Here are a couple more ideas and "extensions" which might be worth exploring.
On 64-bit systems, pointers are 64 bits (8 bytes), which is quite a lot. Instead you could use 32 bits (4 bytes) self relative pointers for the Trie node pointers. This should work well with linear allocators.
I haven't benchmarked this, but the following benchmark done by Chris Wellons shows compressed version not only saving a huge amount of memory, but actually outperforming uncompressed variant at larger Ns (perhaps due to better cache utilization?). However, keep in mind that Chris' benchmark is done with integer keys. Things might be a lot different with string keys.
Due to alignment requirements, the lowest couple bits of the node pointer is going to be 0-ed. Those bits can be used to smuggle extra bits of information. For example smuggling some of the hash bits for the hash-trie in order to avoid the string comparison in case of a hash mismatch may yield better performance.
Assuming your platform supports atomic operations on pointer sized objects, a fairly safe assumption, then it's pretty easy to turn a hash-trie into a lock-free concurrent hashmap using only an atomic load for loading the node and atomic compare-and-exchange for insertion.
How would you deal with potentially malicious input? The exact same way hash-tables deal with it, by using a secure hash-function (e.g siphash) with a secure seed.
Instead of shifting the hash, we could detect hash collisions and go for a rehash. In theory, this should improve cases where you're inserting large amount of items and hash collisions are likely. In my benchmarks with 64-bit hashes however, it made no difference.
Instead of shifting the hash, you could use the hash as the initial seed for a PRNG and use the PRNG's output sequence to traverse the trie. In my synthetic benchmarks with string keys, this didn't really make any difference.
Also beware not to do this when you have a hash function which doesn't produce collisions (e.g an integer hash). Since if you have collision-free hash, then the raw hash will provide a small worst case guarantee but a PRNG will not.
Here's a nice and pretty bar chart summarizing the benchmark data (also here's the benchmark code):
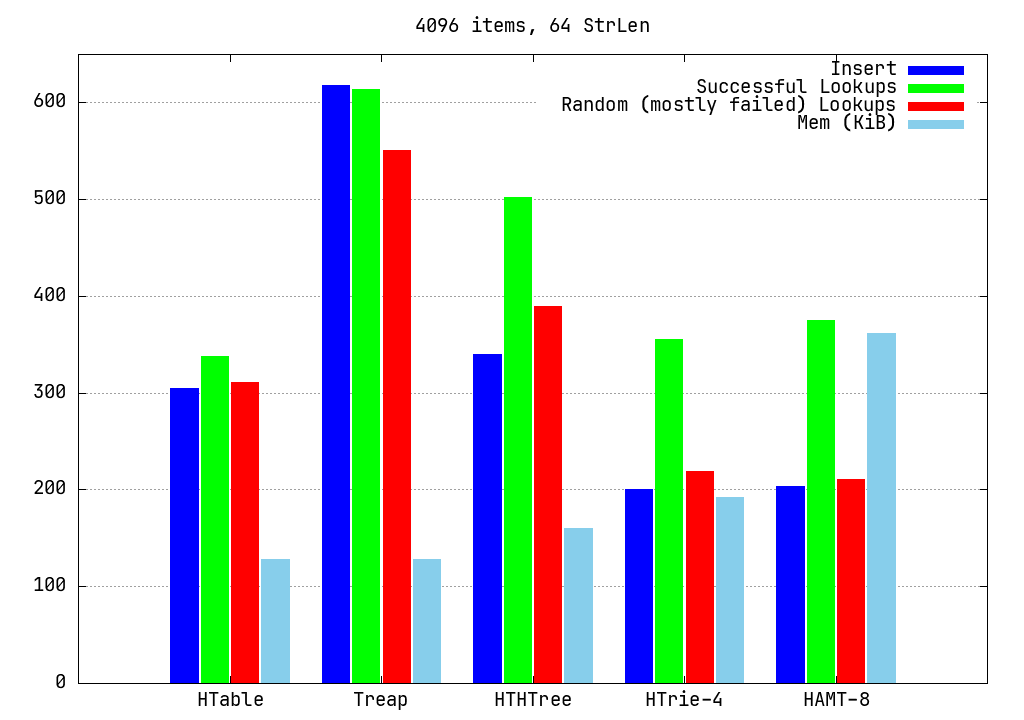
Here are my takeaways for the time being:
